

GROMACS — với Ice Lake trên Máy chủ Dell EMC PowerEdge
Bộ xử lý có khả năng thay đổi Intel Xeon® thế hệ thứ 3 (mã kiến trúc có tên là Ice Lake ) là sản phẩm kế thừa Cascade Lake của Intel. Các tính năng mới bao gồm tối đa 40 lõi cho mỗi bộ xử lý, tám kênh bộ nhớ hỗ trợ tốc độ bộ nhớ 3200 MT/s và PCIe Gen4.
HPC và Phòng thí nghiệm đổi mới trí tuệ nhân tạo tại Dell EMC có quyền truy cập vào một số hệ thống và blog này trình bày kết quả nghiên cứu điểm chuẩn ban đầu của chúng tôi về ứng dụng động lực học phân tử nguồn mở phổ biến – GROningen MAchine for Chemical Simulations ( GROMACS ).
Mô phỏng động lực học phân tử (MD) là một kỹ thuật phổ biến để nghiên cứu hành vi nguyên tử của bất kỳ hệ thống phân tử nào. Nó thực hiện phân tích quỹ đạo của các nguyên tử và phân tử nơi động lực học của hệ thống tiến triển theo thời gian.
Tại HPC và Phòng thí nghiệm đổi mới trí tuệ nhân tạo, chúng tôi đã tiến hành nghiên cứu về nghiên cứu SARS-COV-2, trong đó các ứng dụng như GROMACS đã giúp các nhà nghiên cứu xác định các phân tử liên kết với protein hình gai của vi rút và ngăn không cho vi rút lây nhiễm sang tế bào người. Các trường hợp sử dụng khác của mô phỏng MD trong sinh học y học là thiết kế thuốc lặp đi lặp lại thông qua dự đoán kết nối phối tử protein (trong trường hợp này thường mô hình hóa một loại thuốc để nhắm mục tiêu tương tác protein).
Tổng quan về GROMACS
GROMACS là một gói linh hoạt để thực hiện các mô phỏng MD, chẳng hạn như mô phỏng các phương trình chuyển động của Newton cho các hệ thống có hàng trăm đến hàng triệu hạt. GROMACS có thể chạy trên CPU và GPU ở cấu hình một nút và đa nút (cụm). Nó là một phần mềm mã nguồn mở, miễn phí được phát hành theo Giấy phép Công cộng GNU (GPL). Kiểm tra trang này để biết thêm chi tiết về GROMACS.
Cấu hình phần cứng và phần mềm
Bảng 1: Chi tiết phòng thử nghiệm phần cứng và phần mềm
|
Thành phần |
Máy chủ Dell EMC PowerEdge R750 | Máy chủ Dell EMC PowerEdge R750 | Máy chủ Dell EMC PowerEdge C6520 | Máy chủ Dell EMC PowerEdge C6520 | Máy chủ Dell EMC PowerEdge C6420 | Máy chủ Dell EMC PowerEdge C6420 |
| Mã hàng | xeon 8380 | xeon 8358 | Xeon 8352Y | xeon6330 | xeon 8280 | Xeon 6252 |
| Lõi/ổ cắm | 40 | 32 | 32 | 28 | 28 | 24 |
| tần số cơ sở | 2,30 GHz | 2,60 GHz | 2,20 GHz | 2,00 GHz | 2,70 GHz | 2,10 – GHz |
| TDP | 270W | 250W | 205 W | 205 W | 205 W | 150W |
| L3Cache | 60M | 48M | 48M | 42M | 38,5 triệu | 37.75M |
| Hệ điều hành | Red Hat Enterprise Linux 8.3 4.18.0-240.22.1.el8_3.x86_64 | |||||
| Kỉ niệm | 16 GB x 16 (2Rx8) 3200 tấn/giây | 16 GB x 12 (2Rx8)
2933 tấn/giây |
||||
| BIOS/CPLD | 1.1.2/1.0.1 | |||||
| kết nối | NVIDIA Mellanox HDR | NVIDIA Mellanox HDR100 | ||||
| Trình biên dịch | Studio song song Intel 2020 (bản cập nhật 4) | |||||
| GROMACS | 2021.1 | |||||
Bộ dữ liệu được sử dụng để phân tích hiệu suất
Bảng 2: Mô tả các bộ dữ liệu được sử dụng để phân tích hiệu suất
| Bộ dữ liệu/Liên kết tải xuống | Sự mô tả | tĩnh điện | nguyên tử | Kích thước hệ thống |
| Nước uống | chuyển động của nước
Ví dụ này nhằm mô phỏng- quá trình chuyển động của nhiều phân tử nước trong từng không gian và nhiệt độ.
|
Hạt lưới Ewald (PME)
|
1536K | nhỏ bé |
| 3072K | Lớn | |||
| HecBioSim | Ví dụ này là để mô phỏng-
Hệ thống nguyên tử 1,4M – Một cặp bộ điều chỉnh độ sáng hEGFR của 1IVO và 1IVO Hệ thống nguyên tử 3M – Một cặp tetramer hEGFR của 1IVO và 1IVO
|
Hạt lưới Ewald (PME)
|
1,5M | Nhỏ bé |
| 3M | Lớn | |||
| Prace – Lignocellulose | Ví dụ này là để mô phỏng lignocellulose – tpr được lấy từ trang web PRACE
|
Trường phản ứng (rf)
|
3M | Lớn |
Tổng hợp chi tiết
Chúng tôi đã biên dịch GROMACS từ nguồn (phiên bản 2021.1) bằng Trình biên dịch Intel 2020 Update 5 để tận dụng tối ưu hóa AVX2 và AVX512 cũng như thư viện Intel MKL FFT. Phiên bản mới của GROMACS có hiệu suất tăng đáng kể do những cải tiến trong thuật toán song song hóa của nó. Hệ thống xây dựng GROMACS và công cụ gmx mdrun có trí thông minh tích hợp và có thể định cấu hình giúp phát hiện phần cứng của bạn và sử dụng hiệu quả phần cứng đó.
Mục tiêu của Benchmarking
Mục tiêu của chúng tôi là định lượng hiệu suất của GROMACS bằng các trường hợp thử nghiệm khác nhau, chẳng hạn như đánh giá hiệu suất trên các bộ xử lý Ice Lake khác nhau như được liệt kê trong Bảng 1, sau đó chúng tôi so sánh Xeon có thể mở rộng thế hệ thứ 2 và thứ 3 ( Cascade Lake so với Ice Lake) và cuối cùng là chúng tôi so sánh khả năng mở rộng đa nút với bật và tắt siêu phân luồng.
Để đánh giá kết quả của bộ dữ liệu với một số liệu thích hợp, chúng tôi đã thêm các cờ trình biên dịch cấp cao được liên kết, cân bằng tải trường tĩnh điện (như PME, v.v.), được thử nghiệm với nhiều cấp bậc, xếp hạng PME riêng biệt, thay đổi các giá trị danh sách nstlist khác nhau và tạo một mô hình cho chúng tôi ứng dụng (GROMACS).
Thang thời gian điển hình của hệ thống mô phỏng theo thứ tự micro giây (µs) hoặc nano giây (ns). Chúng tôi đo lường hiệu suất cho mô phỏng của tập dữ liệu dưới dạng nano giây mỗi ngày (ns/ngày).
Phân tích hiệu suất trên một nút
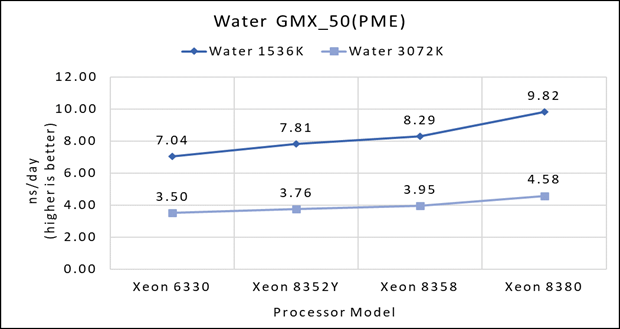
Hình 1(a): Hiệu năng một nút của Water 1536K và Water 3072K trên mẫu bộ xử lý Ice Lake
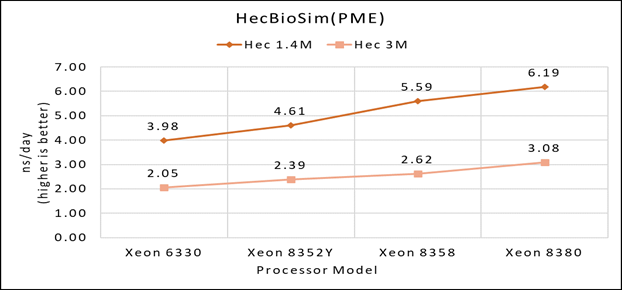 Hình 1(b): Hiệu suất nút đơn của Lignocellulose 3M trên mẫu bộ xử lý Ice Lake
Hình 1(b): Hiệu suất nút đơn của Lignocellulose 3M trên mẫu bộ xử lý Ice Lake
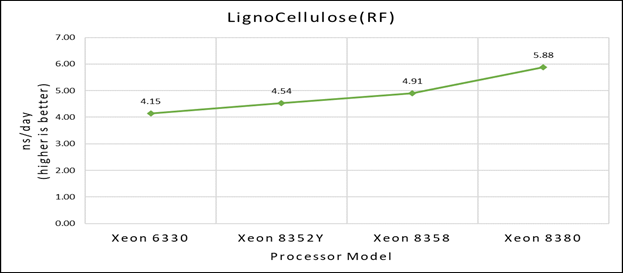 Hình 1(c): Hiệu suất nút đơn của HecBioSim 1.4M và HecBioSim 3M trên mẫu bộ xử lý Ice Lake
Hình 1(c): Hiệu suất nút đơn của HecBioSim 1.4M và HecBioSim 3M trên mẫu bộ xử lý Ice Lake
Hình 1 (a), (b) và (c) cho thấy các phân tích hiệu suất nút đơn cho ba bộ dữ liệu được đề cập trong Bảng 2 với bốn mẫu bộ xử lý có sẵn để đánh giá GROMACS.
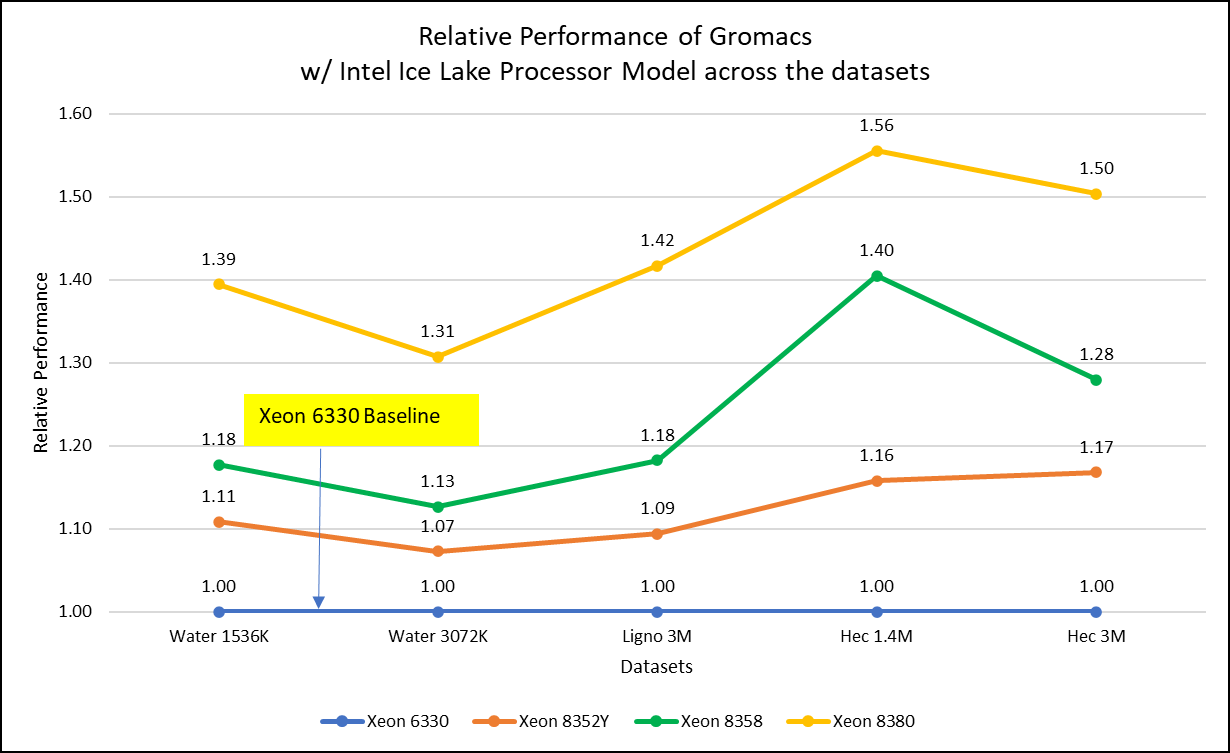
Hình 2: Hiệu suất tương đối của GROMACS trên các bộ dữ liệu với Mô hình bộ xử lý Intel Ice Lake
Để dễ dàng so sánh giữa các bộ dữ liệu khác nhau, hiệu suất tương đối của kiểu bộ xử lý đã được đưa vào một biểu đồ duy nhất. Tuy nhiên, điều đáng chú ý là mỗi bộ dữ liệu hoạt động riêng lẻ khi hiệu suất được xem xét, vì mỗi bộ sử dụng các tệp đầu vào cấu trúc liên kết phân tử (tpr) và tệp cấu hình khác nhau.
Hiệu suất tập dữ liệu riêng lẻ được đề cập tương ứng trong Hình 1(a), 1(b) và 1(c).
Hình 2 cho thấy việc tăng số lượng lõi trong mô hình bộ xử lý sẽ làm tăng hiệu suất, dựa trên bộ dữ liệu được sử dụng. Ở đây, chúng tôi quan sát thấy rằng bộ dữ liệu nhỏ hơn (nước 1536K và HecBioSim 1400K) có lợi thế hơn, tăng hiệu suất từ 5 đến 6% so với bộ dữ liệu lớn hơn (nước 3072, HecBioSim 3M và Ligno 3M).
Tiếp theo, bằng cách so sánh các con số tương đối giữa bộ xử lý cơ sở Xeon 6330(28C) với Xeon 8380(40C), chúng tôi nhận thấy mức tăng hiệu suất từ 30 đến 50 phần trăm theo các bộ dữ liệu có số lõi tăng lên, từ 28 lên 40. là theo tần số của mô hình bộ xử lý.
Phân tích hiệu suất trên Cascade Lake vs Ice Lake
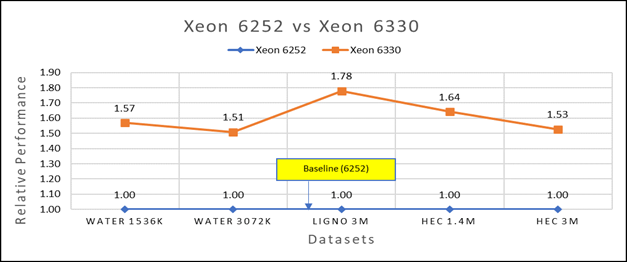
Hình 3(a): Hiệu suất của GROMACS trên Cascade Lake (Xeon 6252) so với Ice Lake (Xeon 6330)
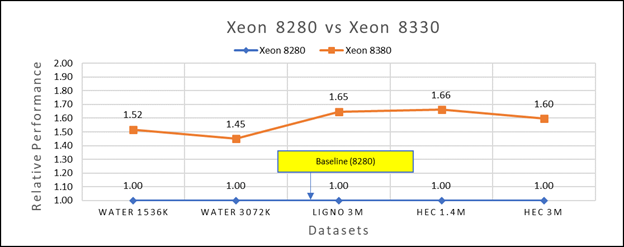
Hình 3(b): Hiệu suất của GROMACS trên Cascade Lake (Xeon 8280) so với Ice Lake (Xeon 8380)
Chúng tôi tính đến thực tế là bộ nhớ phù hợp với bộ dữ liệu. Để bắt đầu, chúng tôi so sánh từng bộ xử lý với các bộ xử lý thế hệ trước. Để so sánh điểm chuẩn hiệu suất, chúng tôi đã chọn Cascade Lake gần nhất với các đối tác Ice Lake của họ về các tính năng phần cứng như kích thước bộ đệm, giá trị TDP và Tần suất cơ sở/Turbo của bộ xử lý và đánh dấu giá trị tối đa đạt được cho Ns/ngày theo từng bộ dữ liệu được đề cập trong Bảng 2.
Hình 3a cho thấy Ice Lake 6330 nhanh hơn 6252 từ 50 đến 75 phần trăm. Xeon 6330 có nhiều lõi hơn 16 phần trăm và băng thông bộ nhớ nhanh hơn 9 phần trăm. Hình 3b cho thấy Ice Lake 8380 nhanh hơn tới 50-65% so với Xeon 8280 trong các bài kiểm tra nút đơn, điều này phù hợp với số lõi nhiều hơn 42% và băng thông bộ nhớ nhanh hơn 9%.
Kết quả này là do tốc độ bộ xử lý cao hơn, trong đó mỗi lõi có thể truy cập nhiều dữ liệu hơn. Ngoài ra, các bộ dữ liệu sử dụng nhiều bộ nhớ hơn và một số tỷ lệ phần trăm được thêm vào do cải thiện tần số hợp lý. Nhìn chung, kết quả của bộ xử lý Ice Lake cho thấy GROMACS cải thiện hiệu suất đáng kể so với bộ xử lý Cascade Lake.
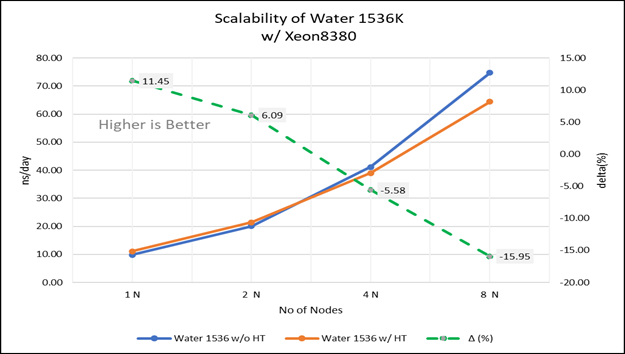
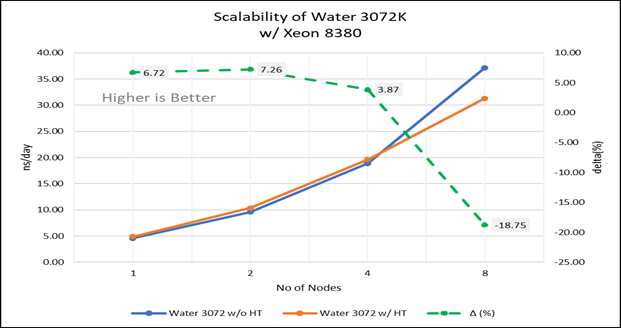
Phân tích hiệu suất trên Đa nút Hình 4 (a): Khả năng mở rộng của nước 1536K khi tắt siêu phân luồng (80C) so với bật siêu phân luồng (160C) w/ Xeon 8380; đường chấm chấm biểu thị vùng đồng bằng giữa bật siêu phân luồng và tắt siêu phân luồng Hình 4 (b): Khả năng mở rộng của nước 3072K khi tắt siêu phân luồng (80C) so với bật siêu phân luồng (160C) w/INTEL 8380; đường chấm chấm biểu thị đồng bằng giữa kích hoạt siêu phân luồng và siêu phân luồng bị vô hiệu hóa

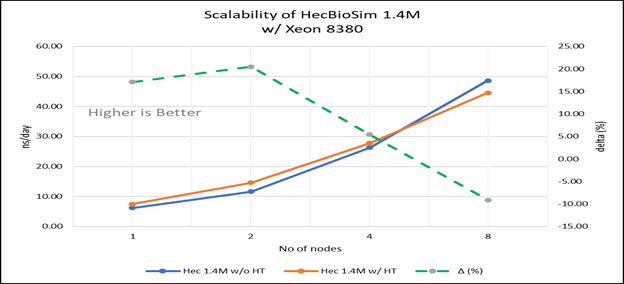 Hình 4 (c): Khả năng mở rộng của HecBioSim 1.4M khi tắt siêu phân luồng (80C) so với bật siêu phân luồng (160C) với Xeon 8380; đường chấm chấm biểu thị đồng bằng giữa kích hoạt siêu phân luồng và siêu phân luồng bị vô hiệu hóa
Hình 4 (c): Khả năng mở rộng của HecBioSim 1.4M khi tắt siêu phân luồng (80C) so với bật siêu phân luồng (160C) với Xeon 8380; đường chấm chấm biểu thị đồng bằng giữa kích hoạt siêu phân luồng và siêu phân luồng bị vô hiệu hóa
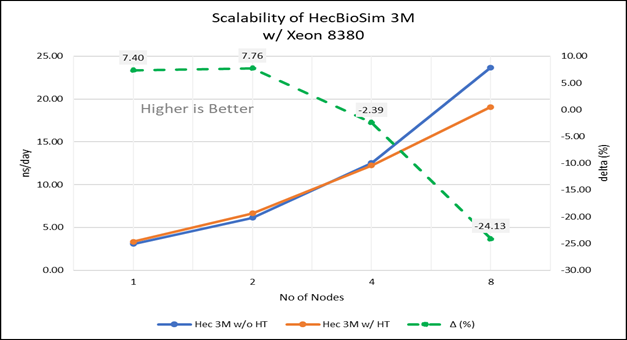 Hình 4 (d): Khả năng mở rộng của HecBioSim 3M khi tắt siêu phân luồng (80C) so với bật siêu phân luồng (160C) với Xeon 8380; đường chấm chấm biểu thị đồng bằng giữa kích hoạt siêu phân luồng và siêu phân luồng bị vô hiệu hóa
Hình 4 (d): Khả năng mở rộng của HecBioSim 3M khi tắt siêu phân luồng (80C) so với bật siêu phân luồng (160C) với Xeon 8380; đường chấm chấm biểu thị đồng bằng giữa kích hoạt siêu phân luồng và siêu phân luồng bị vô hiệu hóa
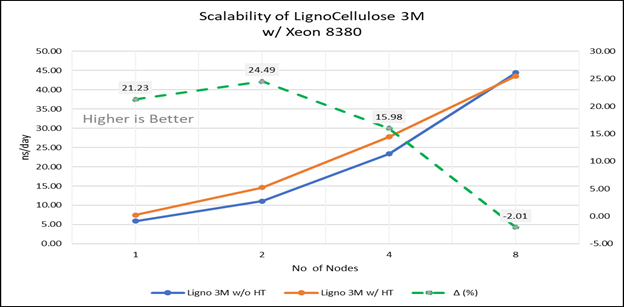 Hình 4 (e): Khả năng mở rộng của Lignocellulose 3M khi tắt siêu phân luồng (80C) so với bật siêu phân luồng (160C) với INTEL 8380 ; đường chấm chấm biểu thị đồng bằng giữa kích hoạt siêu phân luồng và siêu phân luồng bị vô hiệu hóa
Hình 4 (e): Khả năng mở rộng của Lignocellulose 3M khi tắt siêu phân luồng (80C) so với bật siêu phân luồng (160C) với INTEL 8380 ; đường chấm chấm biểu thị đồng bằng giữa kích hoạt siêu phân luồng và siêu phân luồng bị vô hiệu hóa
Đối với các thử nghiệm đa nút, giường thử nghiệm được định cấu hình với kết nối NVIDIA Mellanox HDR chạy ở tốc độ 200 Gbps và mỗi máy chủ có bộ xử lý Ice Lake. Chúng tôi đã có thể đạt được khả năng mở rộng hiệu suất tuyến tính dự kiến cho GROMACS lên đến tám nút khi tắt siêu phân luồng và khoảng 7,25 lần khi bật siêu phân luồng cho tám nút, trên các bộ dữ liệu. Tất cả các lõi trong mỗi máy chủ đều được sử dụng khi chạy các điểm chuẩn này. Hiệu suất tăng gần như tuyến tính trên tất cả các loại tập dữ liệu khi số lượng lõi tăng lên.
Sự kết luận
Các máy chủ Dell EMC Power Edge dựa trên bộ xử lý Ice Lake, với các nâng cấp tính năng phần cứng đáng chú ý so với Cascade Lake, cho thấy mức tăng hiệu suất lên tới 50 đến 60 phần trăm cho tất cả các bộ dữ liệu được sử dụng để đo điểm chuẩn GROMACS. Siêu phân luồng nên bị vô hiệu hóa đối với các điểm chuẩn được đề cập trong blog này để có khả năng mở rộng tốt hơn trên tám nút. Đối với các bộ dữ liệu nhỏ được đề cập trong blog này, lợi ích từ 5 đến 6% so với các bộ dữ liệu lớn hơn với số lượng lõi tăng lên.







